hydrotoolbox.baseflow_sep.usgs_hysep_local¶
- hydrotoolbox.baseflow_sep.usgs_hysep_local(num_days=None, area=None, input_ts='-', columns=None, source_units=None, start_date=None, end_date=None, dropna='no', clean=False, round_index=None, skiprows=None, index_type='datetime', names=None, target_units=None, print_input=False)¶
USGS HYSEP Local minimum graphical method (Sloto and Crouse, 1996)
- Parameters:
num_days (int) –
[optional, default is None, where N is then set to 5 days]
Override the calculation of N days using the area. This is useful for testing the effect of different N days on the baseflow separation.
area (float) –
[optional, default is None, where N is then set to 5 days]
Basin area in km^2.
The area is used to estimate N days using the following equation:
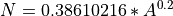
The equation in the HYSEP report expects the area in square miles, but the equation above used in hydrotoolbox is for square kilometers.
input_ts – Streamflow
columns –
[optional, defaults to all columns, input filter]
Columns to select out of input. Can use column names from the first line header or column numbers. If using numbers, column number 1 is the first data column. To pick multiple columns; separate by commas with no spaces. As used in toolbox_utils pick command.
This solves a big problem so that you don’t have to create a data set with a certain column order, you can rearrange columns when data is read in.
source_units (str) –
[optional, default is None, transformation]
If unit is specified for the column as the second field of a ‘:’ delimited column name, then the specified units and the ‘source_units’ must match exactly.
Any unit string compatible with the ‘pint’ library can be used.
start_date (str) –
[optional, defaults to first date in time-series, input filter]
The start_date of the series in ISOdatetime format, or ‘None’ for beginning.
end_date (str) –
[optional, defaults to last date in time-series, input filter]
The end_date of the series in ISOdatetime format, or ‘None’ for end.
dropna (str) –
[optional, defauls it ‘no’, input filter]
Set dropna to ‘any’ to have records dropped that have NA value in any column, or ‘all’ to have records dropped that have NA in all columns. Set to ‘no’ to not drop any records. The default is ‘no’.
clean –
[optional, default is False, input filter]
The ‘clean’ command will repair a input index, removing duplicate index values and sorting.
round_index –
[optional, default is None which will do nothing to the index, output format]
Round the index to the nearest time point. Can significantly improve the performance since can cut down on memory and processing requirements, however be cautious about rounding to a very course interval from a small one. This could lead to duplicate values in the index.
skiprows (list-like or integer or callable) –
[optional, default is None which will infer header from first line, input filter]
Line numbers to skip (0-indexed) if a list or number of lines to skip at the start of the file if an integer.
If used in Python can be a callable, the callable function will be evaluated against the row indices, returning True if the row should be skipped and False otherwise. An example of a valid callable argument would be
lambda x: x in [0, 2].index_type (str) –
[optional, default is ‘datetime’, output format]
Can be either ‘number’ or ‘datetime’. Use ‘number’ with index values that are Julian dates, or other epoch reference.
names (str) –
[optional, default is None, transformation]
If None, the column names are taken from the first row after ‘skiprows’ from the input dataset.
MUST include a name for all columns in the input dataset, including the index column.
target_units (str) –
[optional, default is None, transformation]
The purpose of this option is to specify target units for unit conversion. The source units are specified in the header line of the input or using the ‘source_units’ keyword.
The units of the input time-series or values are specified as the second field of a ‘:’ delimited name in the header line of the input or in the ‘source_units’ keyword.
Any unit string compatible with the ‘pint’ library can be used.
This option will also add the ‘target_units’ string to the column names.
print_input –
[optional, default is False, output format]
If set to ‘True’ will include the input columns in the output table.
tablefmt (str) –
[optional, default is ‘csv’, output format]
The table format. Can be one of ‘csv’, ‘tsv’, ‘plain’, ‘simple’, ‘grid’, ‘pipe’, ‘orgtbl’, ‘rst’, ‘mediawiki’, ‘latex’, ‘latex_raw’ and ‘latex_booktabs’.